1.集成学习
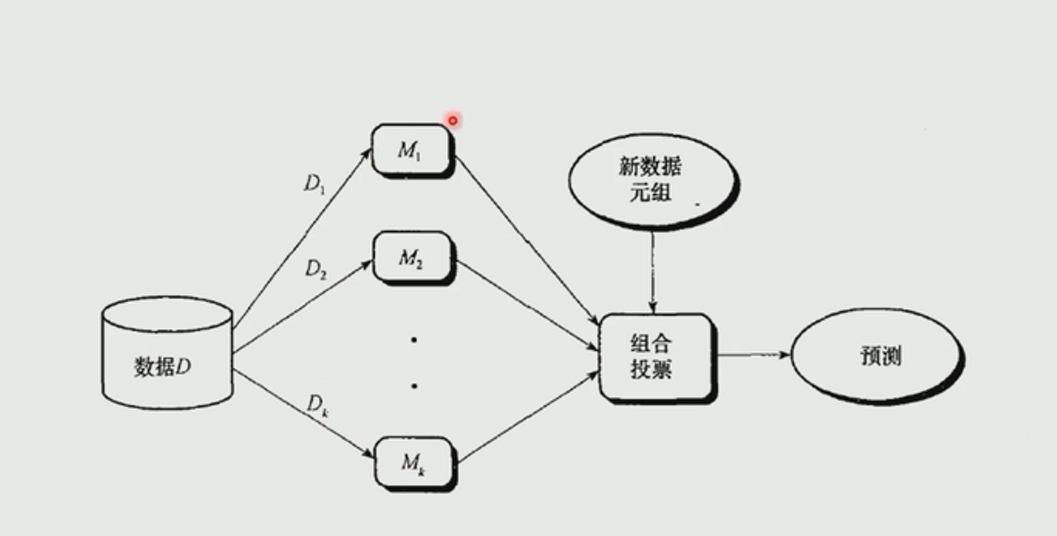
集成学习是一种“博采众长”的思想,他通过构建并结合多个机器学习模型来完成学习任务。假如我们通过训练得到了两个学习器,一个学习器准确率为90%,另一个只有60%,但是对于某一些样本,60%的那个学习器的表现可能会比90%的那个好一些。所以集成学习就是组合多个分类器,最后得到一个更好的分类器。对于训练集,通过训练若干个个体学习器,通过一定的结合策略,最终形成一个强学习器,以达到博采众长的目的。
2.bagging
bagging也叫做bootstrap aggregating,是在原始数据集选择S次后得到S个新数据集的一种技术。是一种又放回的抽样。对于m个样本的原始数据集,我们每次先随机采集一个样本放入采样集,接着把该样本放回,这样采集m次,最终可得到m个样本的采样集,
1 2 3 4 5 6 7 from sklearn import neighborsfrom sklearn import datasetsfrom sklearn.ensemble import BaggingClassifierfrom sklearn import treefrom sklearn.model_selection import train_test_splitimport numpy as npimport matplotlib.pyplot as plt
1 2 3 4 5 iris=datasets.load_iris() x_data=iris.data[:,:2 ] y_data=iris.target x_train,x_test,y_train,y_test=train_test_split(x_data,y_data)
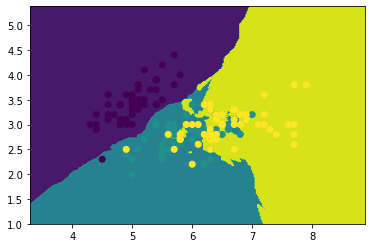
1 2 knn=neighbors.KNeighborsClassifier() knn.fit(x_train,y_train)
KNeighborsClassifier()
1 2 3 4 5 6 7 8 9 10 11 def plot (model ): x_min,x_max=x_data[:,0 ].min ()-1 ,x_data[:,0 ].max ()+1 y_min,y_max=x_data[:,1 ].min ()-1 ,x_data[:,1 ].max ()+1 xx,yy=np.meshgrid(np.arange(x_min,x_max,0.02 ), np.arange(y_min,y_max,0.02 )) z=model.predict(np.c_[xx.ravel(),yy.ravel()]) z=z.reshape(xx.shape) cs=plt.contourf(xx,yy,z)
1 2 3 4 plot(knn) plt.scatter(x_data[:,0 ],x_data[:,1 ],c=y_data) plt.show() knn.score(x_test,y_test)
0.7631578947368421
1 2 dtree=tree.DecisionTreeClassifier() dtree.fit(x_train,y_train)
DecisionTreeClassifier()
1 2 3 4 plot(dtree) plt.scatter(x_data[:,0 ],x_data[:,1 ],c=y_data) plt.show() dtree.score(x_test,y_test)
0.631578947368421
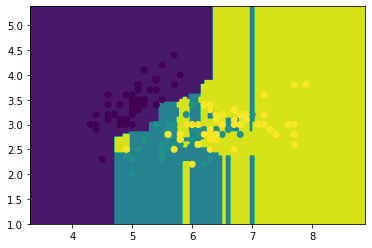
1 2 3 4 5 6 7 bagging_knn=BaggingClassifier(knn,n_estimators=100 ) bagging_knn.fit(x_train,y_train) plot(bagging_knn) plt.scatter(x_data[:,0 ],x_data[:,1 ],c=y_data) plt.show() bagging_knn.score(x_test,y_test)
0.7894736842105263
1 2 3 4 5 6 bagging_tree=BaggingClassifier(dtree,n_estimators=100 ) bagging_tree.fit(x_train,y_train) plot(bagging_tree) plt.scatter(x_data[:,0 ],x_data[:,1 ],c=y_data) plt.show() bagging_tree.score(x_test,y_test)
0.6578947368421053
注意每次运行由于会对数据集随机切分,所以每次运行出来的 结果也会不相同,而且集成学习后的结果也未必会比原来的好,可能相等也可能会下降。
3.随机森林
RF=决策树+Bagging+随机属性选择
随机森林得到流程:
1 2 3 4 5 from sklearn import treefrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifierimport numpy as npimport matplotlib.pyplot as plt
部分数据集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@iZbp173czfyjpvvdm6k4amZ data] 0.051267,0.69956,1 -0.092742,0.68494,1 -0.21371,0.69225,1 -0.375,0.50219,1 -0.51325,0.46564,1 -0.52477,0.2098,1 -0.39804,0.034357,1 -0.30588,-0.19225,1 0.016705,-0.40424,1 0.13191,-0.51389,1 0.38537,-0.56506,1 0.52938,-0.5212,1 0.63882,-0.24342,1
1 2 3 4 5 data=np.genfromtxt("/root/jupyter_projects/data/LR-testSet2.txt" ,delimiter="," ) x_data=data[:,:-1 ] y_data=data[:,-1 ] plt.scatter(x_data[:,0 ],x_data[:,1 ],c=y_data) plt.show()
1 2 3 4 5 6 7 8 9 10 11 12 13 def plot (model ): x_min,x_max=x_data[:,0 ].min ()-1 ,x_data[:,0 ].max ()+1 y_min,y_max=x_data[:,1 ].min ()-1 ,x_data[:,1 ].max ()+1 xx,yy=np.meshgrid(np.arange(x_min,x_max,0.02 ), np.arange(y_min,y_max,0.02 )) z=model.predict(np.c_[xx.ravel(),yy.ravel()]) z=z.reshape(xx.shape) cs=plt.contourf(xx,yy,z) plt.scatter(x_data[:,0 ],x_data[:,1 ],c=y_data) plt.show()
1 x_train,x_test,y_train,y_test=train_test_split(x_data,y_data,test_size=0.2 )
1 2 3 4 detree=tree.DecisionTreeClassifier() detree.fit(x_train,y_train) plot(detree) detree.score(x_test,y_test)
0.7083333333333334
1 2 3 4 RF=RandomForestClassifier(n_estimators=50 ) RF.fit(x_train,y_train) plot(RF) RF.score(x_test,y_test)
0.75
4.boosting
AdaBoost 是英文”adaptive Boosting“(自适应增强)的缩写,他的自适应在于:前一个基本分类器被错误分类的样本的权重会增大,而正确分类的样本的权重会减小,并再次用来训练下一个基本分类器。同时,在每一轮迭代中,加入一个新的弱分类器,直到达到某个预定的足够小的错误率或者达到预先指定的最大迭代次数才确定最终的强分类器。
w 1 = 1 N w_{1}=\frac{1}{N} w 1 = N 1
Adaboost训练过程(注意不同版本用的权重更新计算方式不同)
1 2 3 4 5 6 7 import numpy as npimport matplotlib.pyplot as pltfrom sklearn import treefrom sklearn.ensemble import AdaBoostClassifierfrom sklearn.datasets import make_gaussian_quantilesfrom sklearn.metrics import classification_reportfrom sklearn.model_selection import train_test_split
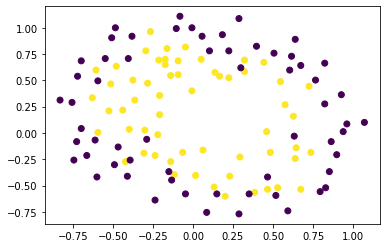
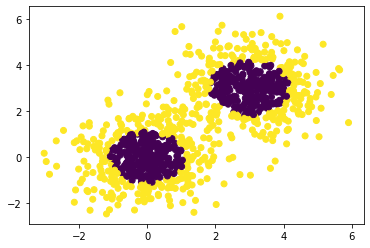
1 2 3 4 5 6 7 8 9 10 x1,y1=make_gaussian_quantiles(n_samples=500 ,n_features=2 ,n_classes=2 ) x2,y2=make_gaussian_quantiles(mean=(3 ,3 ),n_samples=500 ,n_features=2 ,n_classes=2 ) x_data=np.concatenate((x1,x2)) y_data=np.concatenate((y1,-y2+1 )) plt.scatter (x_data[:,0 ],x_data[:,1 ],c=y_data) plt.show()
1 2 3 plt.scatter(x_data[:,0 ],x_data[:,1 ],c=np.concatenate((y1,y2))) plt.show()
1 2 3 4 5 6 7 8 9 10 11 12 13 def plot (model ): x_min,x_max=x_data[:,0 ].min ()-1 ,x_data[:,0 ].max ()+1 y_min,y_max=x_data[:,1 ].min ()-1 ,x_data[:,1 ].max ()+1 xx,yy=np.meshgrid(np.arange(x_min,x_max,0.02 ), np.arange(y_min,y_max,0.02 )) z=model.predict(np.c_[xx.ravel(),yy.ravel()]) z=z.reshape(xx.shape) cs=plt.contourf(xx,yy,z) plt.scatter(x_data[:,0 ],x_data[:,1 ],c=y_data) plt.show()
1 x_train,x_test,y_train,y_test=train_test_split(x_data,y_data)
1 2 3 4 dtree=tree.DecisionTreeClassifier(max_depth=4 ) dtree.fit(x_train,y_train) plot(dtree) dtree.score(x_test,y_test)
0.792
1 2 3 4 5 adaboost_tree=AdaBoostClassifier(dtree,n_estimators=10 ) adaboost_tree.fit(x_train,y_train) plot(adaboost_tree) adaboost_tree.score(x_test,y_test)
0.932
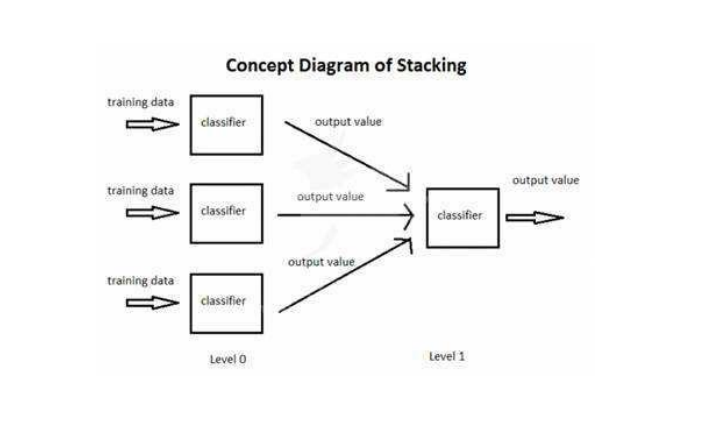
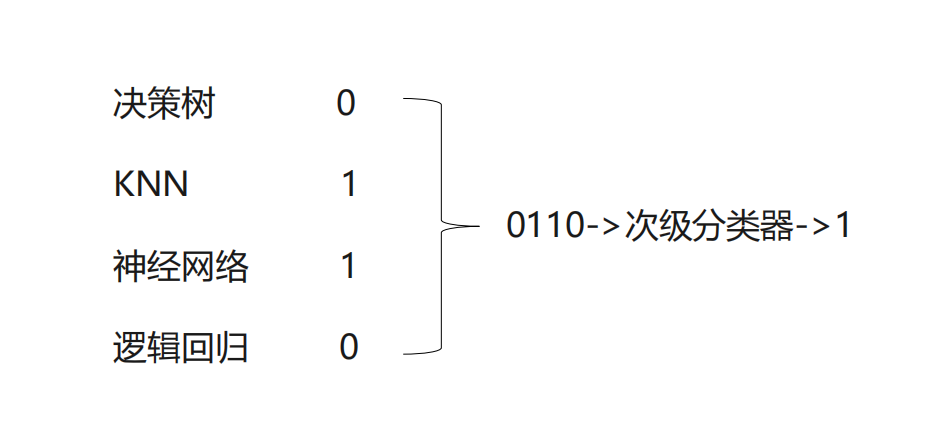
5.Stacking
stacking使用多个不同的分类器对训练集进行预测,把预测得到的结果作为一个次级分类器的输入。次级分类器的输出是整个模型的预测结果。
1 2 3 4 5 6 from sklearn import datasetsfrom sklearn import model_selectionfrom sklearn.linear_model import LogisticRegressionfrom sklearn import neighborsfrom sklearn import treefrom mlxtend.classifier import StackingClassifier
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 iris=datasets.load_iris() x_data=iris.data[:,1 :3 ] y_data=iris.target clf1=neighbors.KNeighborsClassifier(n_neighbors=1 ) clf2=tree.DecisionTreeClassifier() clf3=LogisticRegression() lr=LogisticRegression() sclf=StackingClassifier(classifiers=[clf1,clf2,clf3],meta_classifier=lr) for clf,label in zip ([clf1,clf2,clf3,sclf], ['KNN' ,'Tree' ,'logiitic' ,'Stack' ] ): scores=model_selection.cross_val_score(clf,x_data,y_data,cv=3 ,scoring='accuracy' ) print (scores.mean(),label)
0.9066666666666667 KNN
0.9133333333333334 Tree
0.9533333333333333 logiitic
0.9333333333333332 Stack
投票
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from sklearn.ensemble import VotingClassifieriris=datasets.load_iris() x_data=iris.data[:,1 :3 ] y_data=iris.target clf1=neighbors.KNeighborsClassifier(n_neighbors=1 ) clf2=tree.DecisionTreeClassifier() clf3=LogisticRegression() sclf=VotingClassifier([('knn' ,clf1),('tree' ,clf2),('logic' ,clf3)]) for clf,label in zip ([clf1,clf2,clf3,sclf], ['KNN' ,'Tree' ,'logiitic' ,'voting' ] ): scores=model_selection.cross_val_score(clf,x_data,y_data,cv=3 ,scoring='accuracy' ) print (scores.mean(),label)
0.9066666666666667 KNN
0.9133333333333334 Tree
0.9533333333333333 logiitic
0.9333333333333332 voting


![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8uecJzrU-1642664658367)(output_4_0.png)]](https://img-blog.csdnimg.cn/afbaa935c4a745faaec2515fed5864a6.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vk02tBeq-1642664658369)(output_6_0.png)]](https://img-blog.csdnimg.cn/2d9268aedf9946f0a084590e5bb7c858.png)