感知机
1.感知机模型
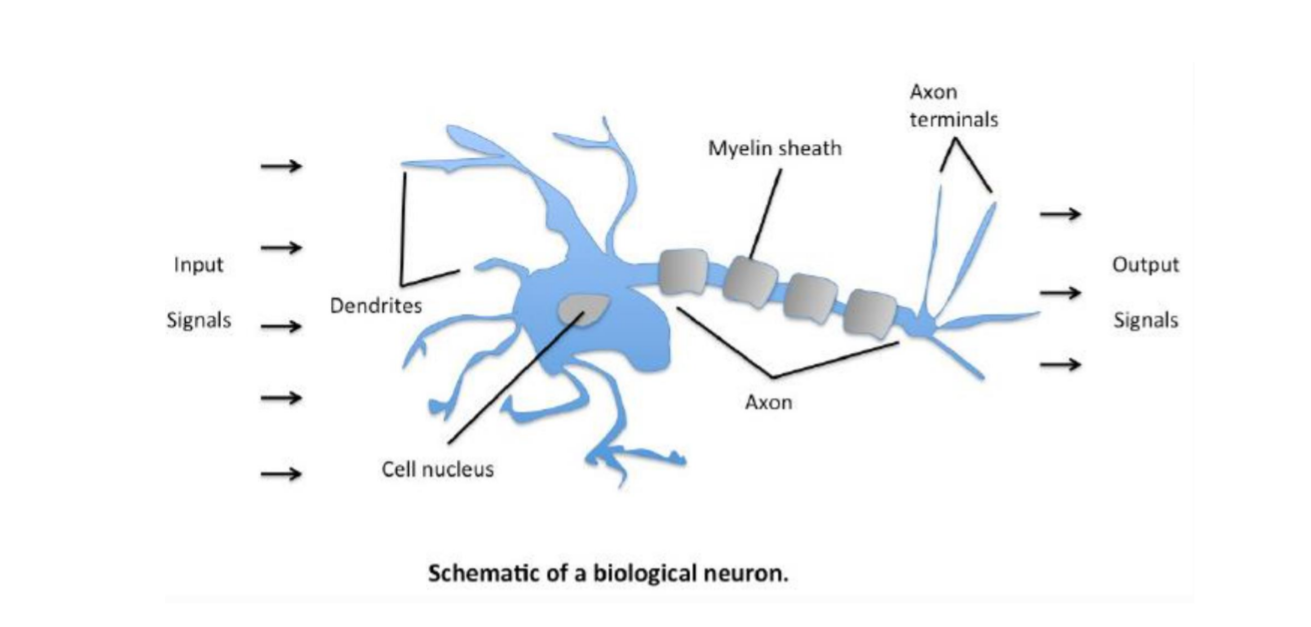
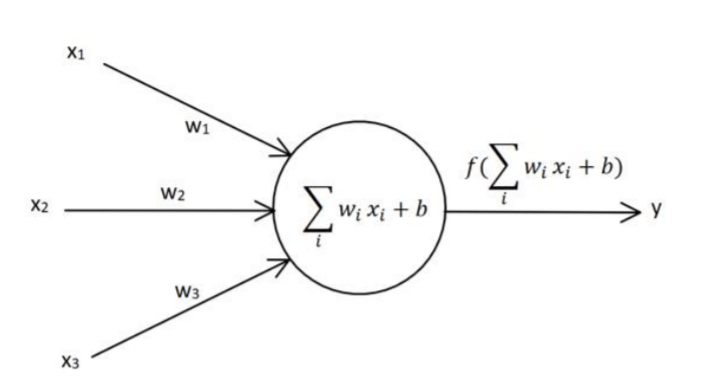
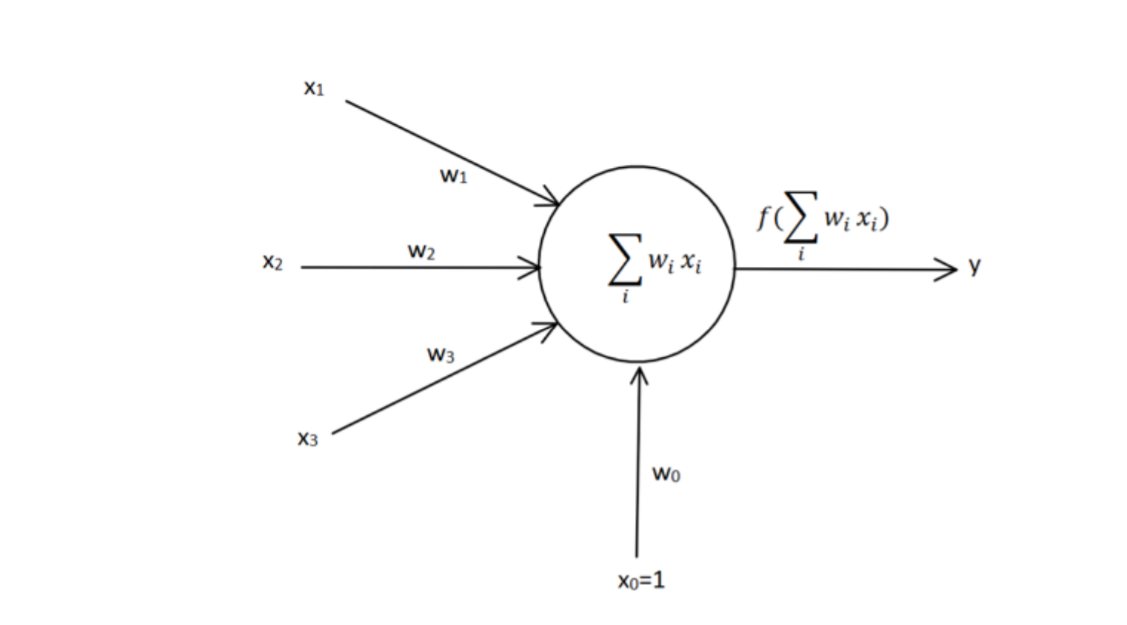
一个单层感知机与人体神经元类似,x 1 , x 2 , x 3 x_{1},x_{2},x_{3} x 1 , x 2 , x 3 w 1 , w 2 , w 3 w_{1},w_{2},w_{3} w 1 , w 2 , w 3
s i g n ( x ) = { 1 , x > = 0 − 1 , x < 0 (1) sign(x)=
\begin{cases}
1,x>=0\\
-1, x<0
\end{cases}
\tag{1}
s i g n ( x ) = { 1 , x >= 0 − 1 , x < 0 ( 1 )
2.感知机的学习策略
对于误分类的样本数据(x,y)来说,( y ^ − y ) ( w x + b ) > 0 (\hat{y}-y)(wx+b)>0 ( y ^ − y ) ( w x + b ) > 0 w x + b > = 0 wx+b>=0 w x + b >= 0 w x + b < 0 wx+b<0 w x + b < 0 ( y ^ − y ) ( w x + b ) > 0 (\hat{y}-y)(wx+b)>0 ( y ^ − y ) ( w x + b ) > 0
L ( w , b ) = ∑ x i ∈ M ( y i ^ − y i ) ( w x i + b ) L(w,b)=\sum_{x_{i}∈M}{(\hat{y_{i}}-y_{i})}(wx_{i}+b)
L ( w , b ) = x i ∈ M ∑ ( y i ^ − y i ) ( w x i + b )
M为误分类点集合
m i n w L ( w ) = m i n w ∑ x ∈ M ( y i ^ − y i ) w x i min_{w}L(w)=min_{w}\sum_{x∈M}{(\hat{y_{i}}-y_{i})wx_{i}}
mi n w L ( w ) = mi n w x ∈ M ∑ ( y i ^ − y i ) w x i
3.感知机的学习算法
感知机学习算法是由误分类驱动的,具体采用随梯度下降法。首先,任意选取一个超平面w 0 b 0 w_{0}b_{0} w 0 b 0
w = w − α ( y i ^ − y i ) x i = w + α ( y i − y ^ ) x i w=w-\alpha (\hat{y_{i}}-y_{i})x_{i}=w+\alpha{(y_{i}-\hat{y})x_{i}}
w = w − α ( y i ^ − y i ) x i = w + α ( y i − y ^ ) x i
所以感知机的学习算法为:w 0 w_{0} w 0 ( x 0 , y 0 ) (x_{0},y_{0}) ( x 0 , y 0 ) ( y i − y i ^ ) ( x i w + b ) < = 0 (y_{i}-\hat{y_i})(x_{i}w+b)<=0 ( y i − y i ^ ) ( x i w + b ) <= 0 w = w + Δ w w=w+\Delta w w = w + Δ w
4.代码实现
1 2 3 import numpy as npimport matplotlib.pyplot as pltimport random
1 2 3 4 5 6 7 8 9 10 11 12 x=np.array([[1 ,3 ,3 ], [1 ,4 ,3 ], [1 ,1 ,1 ], [1 ,0 ,2 ]]) y=np.array([[1 ], [1 ], [-1 ], [-1 ]]) w=np.random.random([3 ,1 ]) lr=0.01 epochs=100 O=0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def plot (): x1 = [3 ,4 ] y1 = [3 ,3 ] x2 = [1 ,0 ] y2 = [1 ,2 ] k = -w[1 ]/w[2 ] d = -w[0 ]/w[2 ] print ('k=' ,k) print ('d=' ,d) xdata=(0 ,5 ) plt.plot(xdata,xdata*k+d,'r' ) plt.scatter(x1,y1,c='b' ) plt.scatter(x2,y2,c='y' ) plt.show()
Δ w = − α ( y i ^ − y i ) x i = α ( y i − y i ^ ) x i \Delta{}w=-\alpha(\hat{y_{i}}-y_{i})x_{i}=\alpha(y_{i}-\hat{y_{i}})x_{i}
Δ w = − α ( y i ^ − y i ) x i = α ( y i − y i ^ ) x i
w = w + Δ w w=w+\Delta w
w = w + Δ w
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def gard (): global x,y,lr,w O=np.sign(np.dot(x,w)) for i in range (x.shape[0 ]): a=x[i,:,np.newaxis].reshape(1 ,-1 ) b=O[i,:,np.newaxis].reshape(1 ,-1 ) if (np.dot(a,w)[0 ,0 ]*(y[i]-b)[0 ,0 ]<0 ): a=x[i,:,np.newaxis].reshape(1 ,-1 ) b=O[i,:,np.newaxis].reshape(1 ,-1 ) w_c=a.T.dot(y[i]-b) w=w+lr*w_c break return w w=np.random.random([3 ,1 ]) for i in range (5000 ): w=gard() O=np.sign(np.dot(x,w)) if (O==y).all (): break plot()
k= [-0.09968292]
d= [2.60720738]
BP神经网络
感知机虽然可以很好的解决线性二分类问题,但是却无法解决非线性的分类问题,甚至连异或这样最简单的的非线性可分的问题。所以便提出了神经网络。
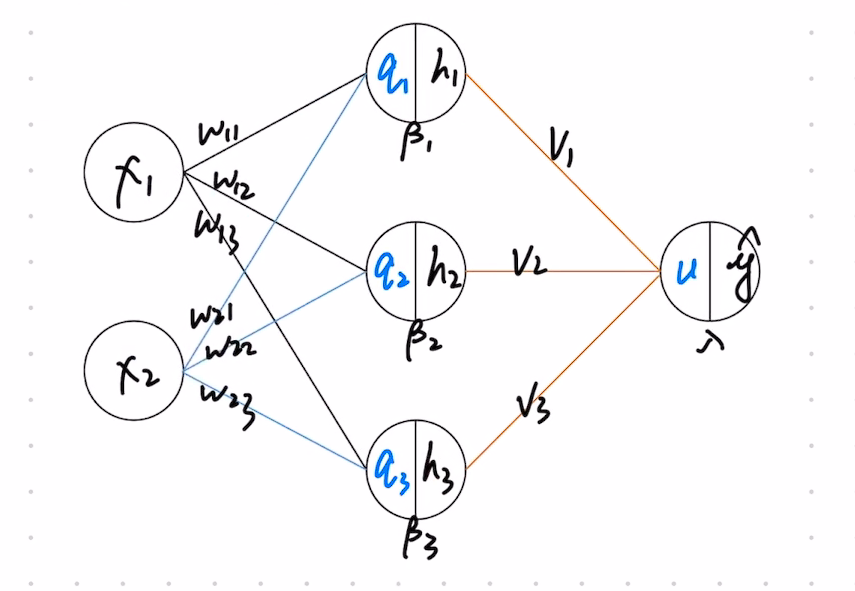
BP神经网络结构
x 1 , x 2 x_{1},x_{2} x 1 , x 2
q i = x 1 w 1 i + x 2 i + x 3 i + β i q_{i}=x_{1}w_{1i}+x_{2i}+x_{3i}+\beta_{i}
q i = x 1 w 1 i + x 2 i + x 3 i + β i
h i = f ( q i ) , f 为激活函数 h_{i}=f(q_{i}) ,f为激活函数
h i = f ( q i ) , f 为激活函数
u ( h 1 v 1 + h 2 v 2 + h 3 v 3 + λ ) u(h_{1}v_{1}+h_{2}v_{2}+h_{3}v_{3}+\lambda)
u ( h 1 v 1 + h 2 v 2 + h 3 v 3 + λ )
y ^ = f ( u ) , f 为激活函数 \hat{y}=f(u),f为激活函数
y ^ = f ( u ) , f 为激活函数
BP神经网络的训练
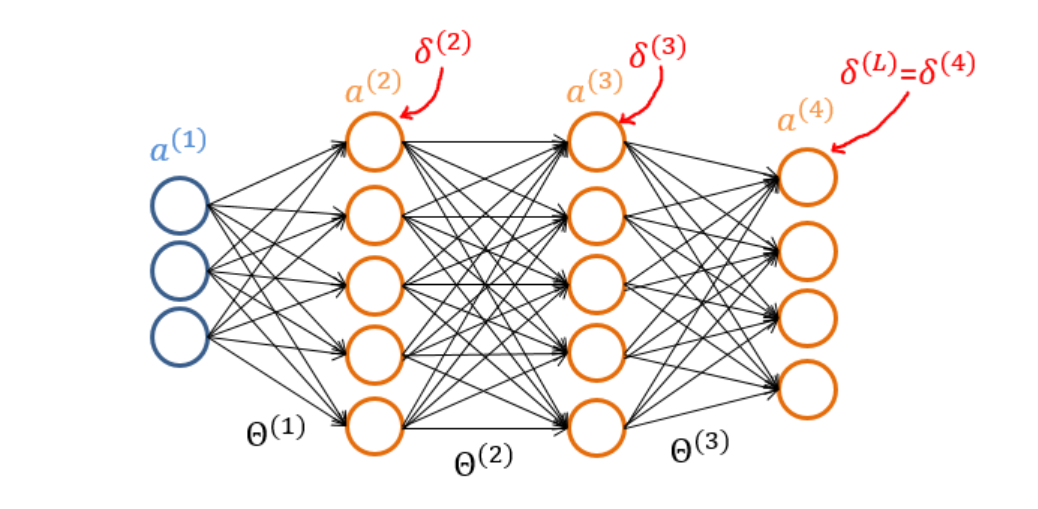
对于BP神经网络,我们采用反向传播算法来求解参数,训练模型。δ \delta δ δ ( n l ) = ( a ( n l ) − y ) ′ ( z ( n l ) ) \delta^{(n_{l})}=(a^{(n_{l})}-y)^{'}(z^{(n_{l})}) δ ( n l ) = ( a ( n l ) − y ) ′ ( z ( n l ) ) δ ( l ) = ( θ ( l ) ) T δ ( l + 1 ) ⋅ ∗ f ′ ( z ( l ) ) \delta^{(l)}=(\theta^{(l)})^{T}\delta^{(l+1)}·*f^{'}(z^{(l)}) δ ( l ) = ( θ ( l ) ) T δ ( l + 1 ) ⋅ ∗ f ′ ( z ( l ) ) ∇ θ ( l ) J = δ ( l + 1 ) ( a ( l ) ) T \nabla_{\theta^{(l)}}J=\delta^{(l+1)}(a^{(l)})^{T} ∇ θ ( l ) J = δ ( l + 1 ) ( a ( l ) ) T ∇ b ( l ) J = δ ( l + 1 ) \nabla_{b^{(l)}}J=\delta^{(l+1)} ∇ b ( l ) J = δ ( l + 1 ) Δ θ ( l ) = 0 , Δ b ( l ) = 0 \Delta{\theta^{(l)}}=0,\Delta{b^{(l)}}=0 Δ θ ( l ) = 0 , Δ b ( l ) = 0 ∇ θ ( l ) J \nabla_{\theta^{(l)}}J ∇ θ ( l ) J ∇ b ( l ) J \nabla_{b^{(l)}}J ∇ b ( l ) J Δ θ ( l ) = Δ θ ( l ) + ∇ θ ( l ) J \Delta{\theta^{(l)}}=\Delta{\theta^{(l)}}+\nabla_{\theta^{(l)}}J Δ θ ( l ) = Δ θ ( l ) + ∇ θ ( l ) J Δ b ( l ) = Δ b ( l ) + ∇ b ( l ) J \Delta{b^{(l)}}=\Delta{b^{(l)}}+\nabla_{b^{(l)}}J Δ b ( l ) = Δ b ( l ) + ∇ b ( l ) J θ ( l ) = θ ( l ) − α 1 m Δ θ ( l ) \theta^{(l)}=\theta^{(l)}-\alpha{\frac{1}{m}\Delta{\theta^{(l)}}} θ ( l ) = θ ( l ) − α m 1 Δ θ ( l ) b ( l ) = b ( l ) − α 1 m Δ b ( l ) b^{(l)}=b^{(l)}-\alpha{\frac{1}{m}\Delta{b^{(l)}}} b ( l ) = b ( l ) − α m 1 Δ b ( l )
反向传播算法推导
首先构造损失函数L = 1 2 ( y ^ − y ) 2 L=\frac{1}{2}(\hat{y}-y)^{2} L = 2 1 ( y ^ − y ) 2
∂ L ∂ v = ∂ L ∂ u ∂ u ∂ v = ∂ L ∂ y ^ ∂ y ^ ∂ u ∂ u ∂ v = ( h ^ − y ) f ’ ( u ) h \frac{\partial{L}}{\partial{v}}=\frac{\partial{L}}{\partial{u}}\frac{\partial{u}}{\partial{v}}=\frac{\partial{L}}{\partial{\hat{y}}}\frac{\partial{\hat{y}}}{\partial{u}}\frac{\partial{u}}{\partial{v}}=(\hat{h}-y)f^{’}(u)h
∂ v ∂ L = ∂ u ∂ L ∂ v ∂ u = ∂ y ^ ∂ L ∂ u ∂ y ^ ∂ v ∂ u = ( h ^ − y ) f ’ ( u ) h
∂ L ∂ w = ∂ L ∂ q ∂ q ∂ w = ∂ L ∂ y ^ ∂ y ^ ∂ u ∂ u ∂ h ∂ h ∂ q ∂ q ∂ w = ( h ^ − y ) f ’ ( u ) v f ’ ( q ) x \frac{\partial{L}}{\partial{w}}=\frac{\partial{L}}{\partial{q}}\frac{\partial{q}}{\partial{w}}=\frac{\partial{L}}{\partial{\hat{y}}}\frac{\partial{\hat{y}}}{\partial{u}}\frac{\partial{u}}{\partial{h}}\frac{\partial{h}}{\partial{q}}\frac{\partial{q}}{\partial{w}}=(\hat{h}-y)f^{’}(u)vf^{’}(q)x
∂ w ∂ L = ∂ q ∂ L ∂ w ∂ q = ∂ y ^ ∂ L ∂ u ∂ y ^ ∂ h ∂ u ∂ q ∂ h ∂ w ∂ q = ( h ^ − y ) f ’ ( u ) v f ’ ( q ) x
利用链式法则来计算梯度更新权重方法简单,但是计算出来的结果过于冗长。由于更新的过程可以看做是从网络的输入层到输出层从前往后更新,每次更新的时候都需要重新计算节点的误差,因此会存在一些不必要的重复计算。其实对于已经计算完毕的节点我们完全可以直接拿来用,因此我们可以重新看待这个问题,从后往前更新。先更新后边的权重,之后再在此基础上利用更新后边的权重产生的中间值来更新较靠前的参数。所有引入了中间变量δ \delta δ ∂ L ∂ ( h 或 q ) \frac{\partial{L}}{\partial{(h或q)}} ∂ ( h 或 q ) ∂ L δ = ∂ L ∂ ( h 或 q ) \delta=\frac{\partial{L}}{\partial{(h或q)}} δ = ∂ ( h 或 q ) ∂ L ∂ L ∂ v = ∂ L ∂ u ∂ u ∂ v = δ 3 h , δ 3 = ( y ^ − y ) f ’ ( u ) \frac{\partial{L}}{\partial{v}}=\frac{\partial{L}}{\partial{u}}\frac{\partial{u}}{\partial{v}}=\delta^{3}h,\delta^{3}=(\hat{y}-y)f^{’}(u) ∂ v ∂ L = ∂ u ∂ L ∂ v ∂ u = δ 3 h , δ 3 = ( y ^ − y ) f ’ ( u ) ∂ L ∂ w = ∂ L ∂ q ∂ q ∂ w = δ 2 x , δ 2 = ( h ^ − y ) f ’ ( u ) v f ’ ( q ) = δ 3 v f ’ ( q ) \frac{\partial{L}}{\partial{w}}=\frac{\partial{L}}{\partial{q}}\frac{\partial{q}}{\partial{w}}=\delta^{2}x,\delta^{2}=(\hat{h}-y)f^{’}(u)vf^{’}(q)=\delta^{3}vf^{’}(q) ∂ w ∂ L = ∂ q ∂ L ∂ w ∂ q = δ 2 x , δ 2 = ( h ^ − y ) f ’ ( u ) v f ’ ( q ) = δ 3 v f ’ ( q )
是不是根据归纳出来的有些牵强,下面我们来证明这个式子:x 0 : 偏置, x 0 = 1 x_{0}:偏置,x_{0}=1 x 0 : 偏置, x 0 = 1 θ : 权重 \theta:权重 θ : 权重 a i ( j ) : 代表第 j 层第 i 个激活单元 a^{(j)}_{i}:代表第j层第i个激活单元 a i ( j ) : 代表第 j 层第 i 个激活单元 z i ( j ) :代表第 j 层第 i 个为未经激活函数的值, a i ( j ) = f ( z i ( j ) ) z^{(j)}_{i}:代表第j层第i个为未经激活函数的值,a^{(j)}_{i}=f(z^{(j)}_{i}) z i ( j ) :代表第 j 层第 i 个为未经激活函数的值, a i ( j ) = f ( z i ( j ) ) θ ( j ) : 代表第 j 层到第 j + 1 层的权重矩阵 \theta^{(j)}:代表第j层到第j+1层的权重矩阵 θ ( j ) : 代表第 j 层到第 j + 1 层的权重矩阵 θ v , u ( j ) : 第 j 成的第 u 各到第 j + 1 层的第 v 个单元的权重。 \theta^{(j)}_{v,u}:第j成的第u各到第j+1层的第v个单元的权重。 θ v , u ( j ) : 第 j 成的第 u 各到第 j + 1 层的第 v 个单元的权重。 如果第 j 层有 m 个单元,第 j 加一层有 n 个单元,那么 θ ( j ) 将会是一个 n ∗ ( m + 1 )的矩阵 如果第j层有m个单元,第j加一层有n个单元,那么\theta^{(j)}将会是一个n*(m+1)的矩阵
如果第 j 层有 m 个单元,第 j 加一层有 n 个单元,那么 θ ( j ) 将会是一个 n ∗ ( m + 1 )的矩阵
我们的激活函数为:J = 1 2 ( y ^ − y ) 2 J=\frac{1}{2}(\hat{y}-y)^{2} J = 2 1 ( y ^ − y ) 2 δ ( j ) = ∂ J ∂ z ( j ) \delta^{(j)}=\frac{\partial{J}}{\partial {z^{(j)}}} δ ( j ) = ∂ z ( j ) ∂ J δ ( l ) = ∂ J ∂ z ( l ) \delta^{(l)}=\frac{\partial{J}}{\partial {z^{(l)}}} δ ( l ) = ∂ z ( l ) ∂ J = ∂ z ( l ) 1 2 ( y ^ − y ) 2 =\frac{\partial} {z^{(l)}}\frac{1}{2}(\hat{y}-y)^{2} = z ( l ) ∂ 2 1 ( y ^ − y ) 2 = ∂ z ( l ) 1 2 ( a ( l ) − y ) 2 =\frac{\partial} {z^{(l)}}\frac{1}{2}(a^{(l)}-y)^{2} = z ( l ) ∂ 2 1 ( a ( l ) − y ) 2 = ∂ z ( l ) 1 2 ( f ( z ( l ) ) − y ) 2 =\frac{\partial} {z^{(l)}}\frac{1}{2}(f(z^{(l)})-y)^{2} = z ( l ) ∂ 2 1 ( f ( z ( l ) ) − y ) 2 = ( y ^ − y ) ⋅ ∗ f ’ ( z ( l ) ) =(\hat{y}-y)·*f^{’}(z^{(l)}) = ( y ^ − y ) ⋅ ∗ f ’ ( z ( l ) ) δ ( l − 1 ) = ∂ J ∂ z ( l − 1 ) \delta^{(l-1)}=\frac{\partial{J}}{\partial {z^{(l-1)}}} δ ( l − 1 ) = ∂ z ( l − 1 ) ∂ J = ∂ z ( l − 1 ) 1 2 ( y ^ − y ) 2 =\frac{\partial} {z^{(l-1)}}\frac{1}{2}(\hat{y}-y)^{2} = z ( l − 1 ) ∂ 2 1 ( y ^ − y ) 2 = ∂ z ( l − 1 ) 1 2 ( a ( l ) − y ) 2 =\frac{\partial} {z^{(l-1)}}\frac{1}{2}(a^{(l)}-y)^{2} = z ( l − 1 ) ∂ 2 1 ( a ( l ) − y ) 2 = ∂ z ( l − 1 ) 1 2 ( f ( z l ) − y ) 2 =\frac{\partial} {z^{(l-1)}}\frac{1}{2}(f(z^{l})-y)^{2} = z ( l − 1 ) ∂ 2 1 ( f ( z l ) − y ) 2 = ( y ^ − y ) ∂ ∂ z ( l − 1 ) f ( z ( l ) ) =(\hat{y}-y)\frac{\partial}{\partial{z^{(l-1)}}}f(z^{(l)}) = ( y ^ − y ) ∂ z ( l − 1 ) ∂ f ( z ( l ) ) = ( y − y ^ ) f ′ ( z ( l ) ) ∂ z ( l ) ∂ z ( l − 1 ) =(\hat{y-y})f^{'}(z^{(l)})\frac{\partial{z^{(l)}}}{\partial{z^{(l-1)}}} = ( y − y ^ ) f ′ ( z ( l ) ) ∂ z ( l − 1 ) ∂ z ( l ) = δ ( l ) ∂ ( f ( z ( l − 1 ) ) θ ( l − 1 ) ) ∂ z ( l − 1 ) =\delta^{(l)}\frac{\partial(f(z^{(l-1)})\theta^{(l-1)})}{\partial{z^{(l-1)}}} = δ ( l ) ∂ z ( l − 1 ) ∂ ( f ( z ( l − 1 ) ) θ ( l − 1 ) ) = δ ( l ) θ ( l − 1 ) f ′ ( z ( l − 1 ) ) =\delta^{(l)}\theta^{(l-1)}f^{'}(z^{(l-1)}) = δ ( l ) θ ( l − 1 ) f ′ ( z ( l − 1 ) )
所以:δ ( l ) = δ ( l + 1 ) θ ( l ) ⋅ ∗ f ′ ( z ( l ) ) \delta^{(l)}=\delta^{(l+1)}\theta^{(l)}·*f^{'}(z^{(l)}) δ ( l ) = δ ( l + 1 ) θ ( l ) ⋅ ∗ f ′ ( z ( l ) ) ∂ J θ ( l ) \frac{\partial{J}}{\theta^{(l)}} θ ( l ) ∂ J = ∂ J ∂ z l + 1 ∂ z ( l + 1 ) ∂ θ ( l ) =\frac{\partial{J}}{\partial{z^{l+1}}}\frac{\partial{z^{(l+1)}}}{\partial{\theta^{(l)}}} = ∂ z l + 1 ∂ J ∂ θ ( l ) ∂ z ( l + 1 ) z ( l + 1 ) = θ ( l ) a ( l ) z^{(l+1)}=\theta^{(l)}a^{(l)} z ( l + 1 ) = θ ( l ) a ( l ) ∂ z ( l + 1 ) ∂ θ ( l ) = a ( l ) \frac{\partial{z^{(l+1)}}}{\partial{\theta^{(l)}}}=a^{(l)} ∂ θ ( l ) ∂ z ( l + 1 ) = a ( l ) ∂ J ∂ z l + 1 = δ ( l + 1 ) \frac{\partial{J}}{\partial{z^{l+1}}}=\delta^{(l+1)} ∂ z l + 1 ∂ J = δ ( l + 1 )
∂ J ∂ θ ( l ) = δ ( l + 1 ) a ( l ) \frac{\partial{J}}{\partial{\theta^{(l)}}}=\delta^{(l+1)}a^{(l)}
∂ θ ( l ) ∂ J = δ ( l + 1 ) a ( l )
对于激活函数为sigmoid函数,f ′ ( z l ) = a ( l ) ( 1 − a ( l ) ) f^{'}(z^{l})=a^{(l)}(1-a^{(l)}) f ′ ( z l ) = a ( l ) ( 1 − a ( l ) )
g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}}
g ( z ) = 1 + e − z 1
g ′ ( z ) = e − z ( 1 + e − z ) 2 g^{'}(z)=\frac{e^{-z}}{(1+e^{-z})^{2}} g ′ ( z ) = ( 1 + e − z ) 2 e − z = 1 1 + e − z e − z 1 + e − z =\frac{1}{1+e^{-z}}\frac{e^{-z}}{1+e^{-z}} = 1 + e − z 1 1 + e − z e − z
= 1 1 + e − z ( 1 + e − z 1 + e − z − 1 1 + e − z ) =\frac{1}{1+e^{-z}}(\frac{1+e^{-z}}{1+e^{-z}}-\frac{1}{1+e^{-z}}) = 1 + e − z 1 ( 1 + e − z 1 + e − z − 1 + e − z 1 )
= g ( z ) ( 1 − g ( z ) ) =g(z)(1-g(z)) = g ( z ) ( 1 − g ( z )) δ ( l ) = a L − y \delta^{(l)}=a^{L}-y δ ( l ) = a L − y
证明如下:
J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) l o g ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − ( h θ ( x ( i ) ) ) ) ] J(\theta)=-\frac{1}{m}\sum_{i=1}^{m}[y^{(i)}log(h_{\theta}(x^{(i)}))+(1-y^{(i)})log(1-(h_{\theta}(x^{(i)})))]
J ( θ ) = − m 1 i = 1 ∑ m [ y ( i ) l o g ( h θ ( x ( i ) )) + ( 1 − y ( i ) ) l o g ( 1 − ( h θ ( x ( i ) )))]
h θ ( x ) = a ( L ) = g ( z ( L ) ) h_{\theta}(x)=a^{(L)}=g(z^{(L)}) h θ ( x ) = a ( L ) = g ( z ( L ) ) g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}} g ( z ) = 1 + e − z 1
J ( θ ) = − y l o g ( 1 1 + e − z ) − ( 1 − y ) l o g ( 1 − 1 1 + e − z ) J(\theta)=-ylog(\frac{1}{1+e^{-z}})-(1-y)log(1-\frac{1}{1+e^{-z}})
J ( θ ) = − y l o g ( 1 + e − z 1 ) − ( 1 − y ) l o g ( 1 − 1 + e − z 1 )
= y l o g ( 1 + e − z ) − ( 1 − y ) l o g ( e − z 1 + e − z ) =ylog(1+e^{-z})-(1-y)log(\frac{e^{-z}}{1+e^{-z}}) = y l o g ( 1 + e − z ) − ( 1 − y ) l o g ( 1 + e − z e − z )
= y l o g ( 1 + e − z ) + ( 1 − y ) l o g ( 1 + e z ) =ylog(1+e^{-z})+(1-y)log(1+e^{z}) = y l o g ( 1 + e − z ) + ( 1 − y ) l o g ( 1 + e z )
δ ( l ) = ∂ ∂ z ( l ) J ( θ ) = ∂ ∂ z ( l ) ( y l o g ( 1 + e − z ( l ) ) + ( 1 − y ) l o g ( 1 + e z ( l ) ) ) \delta^{(l)}=\frac{\partial}{\partial{z^{(l)}}}J(\theta)=\frac{\partial}{\partial{z^{(l)}}}(ylog(1+e^{-z^{(l)}})+(1-y)log(1+e^{z^{(l)}}))
δ ( l ) = ∂ z ( l ) ∂ J ( θ ) = ∂ z ( l ) ∂ ( y l o g ( 1 + e − z ( l ) ) + ( 1 − y ) l o g ( 1 + e z ( l ) ))
= y − e − z ( l ) 1 + e − z ( l ) + ( 1 − y ) e z ( l ) 1 + e z ( l ) =y\frac{-e^{-z^(l)}}{1+e^{-z^{(l)}}}+(1-y)\frac{e^{z^{(l)}}}{1+e^{z^{(l)}}} = y 1 + e − z ( l ) − e − z ( l ) + ( 1 − y ) 1 + e z ( l ) e z ( l )
= − y e ( − z ( l ) ) − y e − z ( l ) e z ( l ) + 1 − y + e z ( l ) − y e ( z l ) ( 1 + e ( − z ( l ) ) ) ( 1 + e ( z ( l ) ) ) =\frac{-ye^{(-z^{(l)})}-ye^{-z^{(l)}}e^{z^{(l)}}+1-y+e^{z^{(l)}}-ye^{(z^{l})}}{(1+e^{(-z^{(l)})})(1+e^{(z^{(l)})})} = ( 1 + e ( − z ( l ) ) ) ( 1 + e ( z ( l ) ) ) − y e ( − z ( l ) ) − y e − z ( l ) e z ( l ) + 1 − y + e z ( l ) − y e ( z l )
= ( 1 − y ) e z ( l ) − ( 1 + e z ( l ) ) y e z − ( l ) + ( 1 − y ) ( 1 + e ( − z ( l ) ) ) ( 1 + e ( z ( l ) ) ) =\frac{(1-y)e^{z^{(l)}}-(1+e^{z^{(l)}})ye^{z^{-(l)}}+(1-y)}{(1+e^{(-z^{(l)})})(1+e^{(z^{(l)})})} = ( 1 + e ( − z ( l ) ) ) ( 1 + e ( z ( l ) ) ) ( 1 − y ) e z ( l ) − ( 1 + e z ( l ) ) y e z − ( l ) + ( 1 − y )
= ( 1 − y ) ( 1 + e ( z ( l ) ) ) ) − ( 1 + e z ( l ) ) y e z − ( l ) ( 1 + e ( − z ( l ) ) ) ( 1 + e ( z ( l ) ) ) =\frac{(1-y)(1+e^{(z^{(l)})}))-(1+e^{z^{(l)}})ye^{z^{-(l)}}}{(1+e^{(-z^{(l)})})(1+e^{(z^{(l)})})} = ( 1 + e ( − z ( l ) ) ) ( 1 + e ( z ( l ) ) ) ( 1 − y ) ( 1 + e ( z ( l ) ) )) − ( 1 + e z ( l ) ) y e z − ( l )
= ( 1 − y − y e − z ( l ) ) ( 1 + e ( z ( l ) ) ) ( 1 + e ( − z ( l ) ) ) ( 1 + e ( z ( l ) ) ) =\frac{(1-y-ye^{-z^{(l)}})(1+e^{(z^{(l)})})}{(1+e^{(-z^{(l)})})(1+e^{(z^{(l)})})} = ( 1 + e ( − z ( l ) ) ) ( 1 + e ( z ( l ) ) ) ( 1 − y − y e − z ( l ) ) ( 1 + e ( z ( l ) ) )
= 1 − y ( 1 − e ( − z ( l ) ) ) ( 1 + e ( − z ( l ) ) ) =\frac{1-y(1-e^{(-z^{(l)})})}{(1+e^{(-z^{(l)})})} = ( 1 + e ( − z ( l ) ) ) 1 − y ( 1 − e ( − z ( l ) ) ) = 1 1 + e − z ( l ) − y =\frac{1}{1+e^{-z^{(l)}}}-y = 1 + e − z ( l ) 1 − y
= g ( z ( l ) ) − y =g(z^{(l)})-y = g ( z ( l ) ) − y
= a ( l ) − y =a^{(l)}-y = a ( l ) − y
即证得δ l = a ( l ) − y \delta^{l}=a^{(l)}-y δ l = a ( l ) − y
神经网络实现手写数字识别
1 2 3 4 5 6 import numpy as npimport matplotlib.pyplot as pltimport matplotlibfrom sklearn.metrics import classification_reportfrom sklearn import datasetsfrom sklearn.model_selection import train_test_split
准备数据
1 2 3 4 5 6 data=datasets.load_digits() x=data.data y=data.target print (X.shape)y.shape
(1797, 64)
(1797,)
1 2 3 4 5 def plot_an_img (img ): fig, ax = plt.subplots(figsize=(1 , 1 )) ax.matshow(img.reshape((8 , 8 )), cmap=matplotlib.cm.binary) plt.xticks(np.array([])) plt.yticks(np.array([]))
1 2 3 4 pick_one = np.random.randint(0 , 1797 ) plot_an_img(x[pick_one, :]) plt.show() print ('this should be {}' .format (y[pick_one]))
this should be 4
1 2 3 4 5 6 7 8 9 10 11 index=np.random.choice(np.arange(X.shape[0 ]),100 ) samples_img=x[index,:] tar=y[index] for i in range (1 ,101 ): plt.subplot(10 ,10 ,i) plt.imshow(samples_img[i-1 ].reshape([8 ,8 ]),cmap=plt.cm.gray_r) plt.text(3 ,10 ,str (tar[i-1 ]),c='r' ) plt.xticks() plt.yticks() plt.show()
1 2 3 X=np.concatenate((np.ones((X.shape[0 ],1 )),X),axis=1 ) print (X[:5 ])print (X.shape)
[[ 1. 0. 0. 5. 13. 9. 1. 0. 0. 0. 0. 13. 15. 10. 15. 5. 0. 0.
3. 15. 2. 0. 11. 8. 0. 0. 4. 12. 0. 0. 8. 8. 0. 0. 5. 8.
0. 0. 9. 8. 0. 0. 4. 11. 0. 1. 12. 7. 0. 0. 2. 14. 5. 10.
12. 0. 0. 0. 0. 6. 13. 10. 0. 0. 0.]
[ 1. 0. 0. 0. 12. 13. 5. 0. 0. 0. 0. 0. 11. 16. 9. 0. 0. 0.
0. 3. 15. 16. 6. 0. 0. 0. 7. 15. 16. 16. 2. 0. 0. 0. 0. 1.
16. 16. 3. 0. 0. 0. 0. 1. 16. 16. 6. 0. 0. 0. 0. 1. 16. 16.
6. 0. 0. 0. 0. 0. 11. 16. 10. 0. 0.]
[ 1. 0. 0. 0. 4. 15. 12. 0. 0. 0. 0. 3. 16. 15. 14. 0. 0. 0.
0. 8. 13. 8. 16. 0. 0. 0. 0. 1. 6. 15. 11. 0. 0. 0. 1. 8.
13. 15. 1. 0. 0. 0. 9. 16. 16. 5. 0. 0. 0. 0. 3. 13. 16. 16.
11. 5. 0. 0. 0. 0. 3. 11. 16. 9. 0.]
[ 1. 0. 0. 7. 15. 13. 1. 0. 0. 0. 8. 13. 6. 15. 4. 0. 0. 0.
2. 1. 13. 13. 0. 0. 0. 0. 0. 2. 15. 11. 1. 0. 0. 0. 0. 0.
1. 12. 12. 1. 0. 0. 0. 0. 0. 1. 10. 8. 0. 0. 0. 8. 4. 5.
14. 9. 0. 0. 0. 7. 13. 13. 9. 0. 0.]
[ 1. 0. 0. 0. 1. 11. 0. 0. 0. 0. 0. 0. 7. 8. 0. 0. 0. 0.
0. 1. 13. 6. 2. 2. 0. 0. 0. 7. 15. 0. 9. 8. 0. 0. 5. 16.
10. 0. 16. 6. 0. 0. 4. 15. 16. 13. 16. 1. 0. 0. 0. 0. 3. 15.
10. 0. 0. 0. 0. 0. 2. 16. 4. 0. 0.]]
(1797, 65)
1 2 3 4 5 6 from sklearn.preprocessing import OneHotEncoderencoder=OneHotEncoder(sparse=False ) y=np.array(y).reshape([-1 ,1 ]) y_onehot=encoder.fit_transform(y) print (y_onehot[:5 ])y_onehot.shape
[[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]]
(1797, 10)
1 2 3 4 5 theta1=np.random.random((25 ,65 ))*0.01 theta2=np.random.random(((10 ,26 )))*0.01 print (theta1.shape)theta2.shape
(25, 65)
(10, 26)
1 2 3 x_train,x_test,y_train,y_test=train_test_split(X,y_onehot) print (x_train.shape,y_train.shape)
(1347, 65) (1347, 10)
1 2 3 4 5 6 def sigmoid (X ): return 1.0 /(1 +np.exp(-X)) def dsigmoid (X ): return np.multiply(sigmoid(X),1 -sigmoid(X))
前向传播
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 parameters={'theta1' :theta1, 'theta2' :theta2} def forward_propagation (X,parameters ): theta1=parameters['theta1' ] theta2=parameters['theta2' ] a1=X z2=np.dot(a1,theta1.T) a2=np.concatenate((np.ones((a1.shape[0 ],1 )),sigmoid(z2)),axis=1 ) z3=np.dot(a2,theta2.T) a3=sigmoid(z3) cache={'a1' :a1, 'z2' :z2, 'a2' :a2, 'z3' :z3, 'a3' :a3 } return a3,cache a3,cache=forward_propagation(X,parameters) a3[:2 ]
array([[0.52583117, 0.5281081 , 0.52749448, 0.52850773, 0.52823992,
0.53030709, 0.53145626, 0.52662732, 0.53041953, 0.52550445],
[0.52648372, 0.52867252, 0.52801463, 0.52926495, 0.5289496 ,
0.53114059, 0.53228084, 0.52725707, 0.53094982, 0.52605496]])
代价函数
1 2 3 4 5 6 7 8 9 10 11 def cost (X,Y,parameters ): a3,cache=forward_propagation(X,parameters) m=X.shape[0 ] first=np.multiply(Y,np.log(a3)) second=np.multiply(1 -Y,np.log(1 -a3)) J=-first-second return J.sum ()/m cost(X,y_onehot,parameters)
7.408890217449401
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def cost_res (X,y,parameters,lamda=1 ): theta1=parameters['theta1' ] theta2=parameters['theta2' ] j=cost(X,y,parameters) m=X.shape[0 ] theta1=np.array(theta1) theta2=np.array(theta2) re_theta1=((theta1[:,1 :])**2 ).sum ()/(2.0 *m) re_theta2=((theta2[:,1 :])**2 ).sum ()/(2.0 *m) J=j+lamda*re_theta1+lamda*re_theta2 return J cost_res(X,y_onehot,parameters)
7.408907648511851
反向传播
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 def backward_propagate (X,y,parameters,lamda=1 ): theta1=parameters['theta1' ] theta2=parameters['theta2' ] m=X.shape[0 ] a3,cache=forward_propagation(X,parameters) a1=cache['a1' ] z2=cache['z2' ] a2=cache['a2' ] z3=cache['z3' ] grad_theta1=grad_theta2=0 for i in range (m): a1i=a1[i,:] z2i=z2[i,:] a2i=a2[i,:] z3i=z3[i,:] a3i=a3[i,:] yi=y[i,:] delta3=(a3i-yi) z2i=np.insert(z2i,0 ,np.ones(1 )) delta2=np.multiply(np.dot(delta3,theta2),dsigmoid(z2i)) delta3=np.matrix(delta3) delta2=np.matrix(delta2) grad_theta2+=delta3.T.dot(np.matrix(a2i)) grad_theta1+=delta2[:,1 :].T.dot(np.matrix(a1i)) grad_theta1/=m grad_theta2/=m lambda_theta1=theta1[:,1 :]*lamda/m lambda_theta2=theta2[:,1 :]*lamda/m grad_theta1[:,1 :]+=lambda_theta1 grad_theta2[:,1 :]+=lambda_theta2 grads={ 'grad_theta1' :grad_theta1, 'grad_theta2' :grad_theta2 } return grads grads=backward_propagate(X,y_onehot,parameters) grad_theta1=grads['grad_theta1' ] grad_theta2=grads['grad_theta2' ] print (grad_theta1.shape)print (grad_theta2.shape)grad_theta1[0 ,:10 ]
(25, 65)
(10, 26)
matrix([[2.75026728e-03, 4.78740411e-06, 8.57156752e-04, 1.43582353e-02,
3.21817921e-02, 3.20213878e-02, 1.53658755e-02, 3.52853630e-03,
3.28875302e-04, 1.67262973e-05]])
更新参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def updata_parameters (parameters,grads,learning_rate=1 ): theta1=parameters['theta1' ] theta2=parameters['theta2' ] grad_theta1=grads['grad_theta1' ] grad_theta2=grads['grad_theta2' ] theta1=theta1-learning_rate*grad_theta1 theta2=theta2-learning_rate*grad_theta2 parameters={ 'theta1' :theta1, 'theta2' :theta2 } return parameters
1 2 3 4 5 6 7 8 9 10 11 def progress (percent, width=50 ): ''' 进度打印功能 :param percent: 进度 :param width: 进度条长度 ''' if percent >= 100 : percent = 100 print ('\r%s %f%%' % ('计算进度' , percent), end='' )
训练模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def nn_model (X,Y,parameters,epochs,learning_rate=1 ,lamda=1 ): J_list=[] for i in range (epochs): a3,cache=forward_propagation(X,parameters) grads=backward_propagate(X,Y,parameters,lamda=lamda) if i%50 ==0 : J=cost_res(X,Y,parameters,lamda) J_list.append(J) print ('csot:' ,J) parameters=updata_parameters(parameters,grads,learning_rate) recv_per = (100 * i/(epochs-1 )) progress(recv_per, width=30 ) return parameters parameters=nn_model(x_train,y_train,parameters,1000 ,0.3 )
csot: 0.3435146285670303
计算进度 4.904905%csot: 0.3332751302454119
计算进度 9.909910%csot: 0.33075159173284324
计算进度 14.914915%csot: 0.32867755006376664
计算进度 19.919920%csot: 0.3267981370452875
计算进度 24.924925%csot: 0.32501450922250563
计算进度 29.929930%csot: 0.32316574164765904
计算进度 34.934935%csot: 0.3182895333581057
计算进度 39.939940%csot: 0.31063714327553094
计算进度 44.944945%csot: 0.30796701871174065
计算进度 49.949950%csot: 0.30041283365746996
计算进度 54.954955%csot: 0.29823956515674244
计算进度 59.959960%csot: 0.2965327545282571
计算进度 64.964965%csot: 0.2949714724876018
计算进度 69.969970%csot: 0.29349755594339266
计算进度 74.974975%csot: 0.2920867477290434
计算进度 79.979980%csot: 0.2907250177923556
计算进度 84.984985%csot: 0.2894035835211862
计算进度 89.989990%csot: 0.2881215629635514
计算进度 94.994995%csot: 0.2868833407001544
计算进度 100.000000%
评估模型
1 2 3 4 5 6 7 8 9 10 11 from sklearn.metrics import classification_reportdef show_accuracy (parameters, X, y ): a3,cache=forward_propagation(X,parameters) y_pred = np.argmax(a3, axis=1 ) + 1 y_true=np.argmax(y_test,axis=1 )+1 print (classification_report(y_true, y_pred)) print (y_pred.shape) show_accuracy(parameters,x_test,y_test)
precision recall f1-score support
1 1.00 1.00 1.00 43
2 1.00 0.98 0.99 42
3 0.98 0.98 0.98 53
4 0.94 0.94 0.94 34
5 1.00 1.00 1.00 44
6 0.96 0.94 0.95 48
7 0.98 1.00 0.99 56
8 0.98 0.98 0.98 42
9 0.97 0.95 0.96 39
10 0.94 0.98 0.96 49
accuracy 0.98 450
macro avg 0.98 0.97 0.97 450
weighted avg 0.98 0.98 0.98 450
(450, 1)

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-290Grk3T-1642044127399)(output_5_1.png)]](https://img-blog.csdnimg.cn/4ebe5308acac464ca1f91570928e44c2.png)